

Dalam dunia pencarian informasi modern, istilah information retrieval disambiguation tutorial mulai sering muncul, terutama di kalangan pengembang, peneliti, dan praktisi data. Di balik istilah yang tampak teknis ini, sebenarnya ada konsep yang sangat dekat dengan aktivitas sehari hari kita, seperti mencari informasi di mesin pencari, menelusuri dokumen di perpustakaan digital, hingga menyaring email di kotak masuk. Artikel ini mengupas secara detail bagaimana proses pelurusan makna atau disambiguation bekerja dalam sistem pencarian informasi, dan bagaimana Anda bisa memahaminya secara bertahap layaknya mengikuti tutorial yang runtut.
Mengapa Information Retrieval Disambiguation Tutorial Penting untuk Dipahami
Banyak orang mengira bahwa mesin pencari hanya mencocokkan kata kunci dengan teks di halaman web. Kenyataannya jauh lebih rumit. Sistem informasi modern harus memahami maksud pengguna, menafsirkan kata yang ambigu, dan memilih hasil yang paling relevan di antara jutaan dokumen. Di sinilah konsep yang dibahas dalam information retrieval disambiguation tutorial menjadi krusial.
Bayangkan Anda mengetik kata “java” di mesin pencari. Apakah yang dimaksud adalah bahasa pemrograman Java, pulau Jawa, atau minuman kopi? Tanpa proses disambiguation, sistem akan kebingungan. Disambiguation adalah kemampuan sistem untuk mengurai ambiguitas makna berdasarkan konteks, sinyal tambahan, dan model statistik atau semantik.
“Semakin maju teknologi pencarian, semakin besar tuntutan agar mesin memahami bahasa manusia, bukan sekadar mencocokkan huruf demi huruf.”
Tutorial tentang information retrieval disambiguation biasanya memandu pembaca dari konsep paling dasar tentang pencarian informasi, lalu naik ke tahapan bagaimana sistem membedakan makna kata, frasa, dan bahkan niat pengguna. Pemahaman ini penting bukan hanya untuk teknisi, tetapi juga untuk jurnalis data, analis bisnis, hingga pembuat kebijakan yang bergantung pada data tekstual dalam jumlah besar.
Fondasi Information Retrieval Sebelum Masuk ke Disambiguation
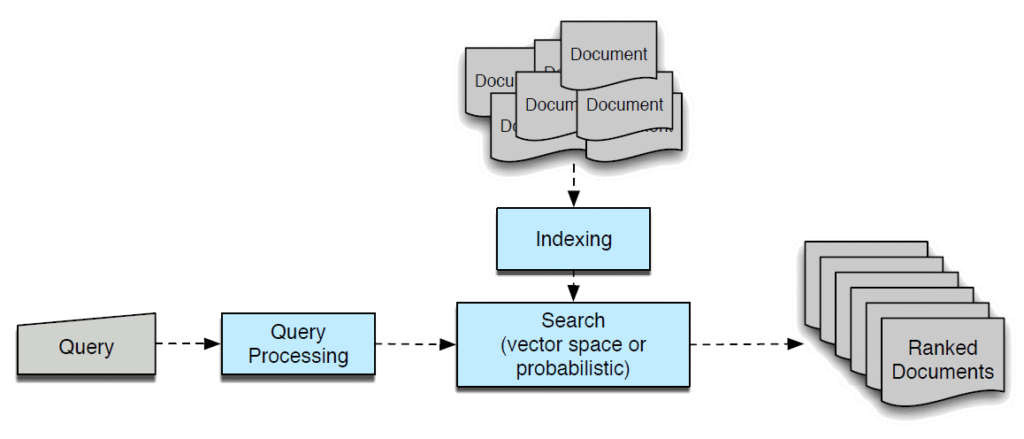
Sebelum mendalami information retrieval disambiguation tutorial, ada baiknya memahami dulu pondasi sistem pencarian informasi. Information retrieval atau IR adalah cabang ilmu komputer yang fokus pada bagaimana menemukan dokumen relevan dari koleksi besar berdasarkan kebutuhan informasi pengguna.
Proses IR klasik biasanya melibatkan beberapa tahapan utama. Pertama, ada pengumpulan dokumen dari berbagai sumber, seperti web, basis data internal, atau arsip digital. Kedua, dokumen diproses dan diindeks, misalnya dengan memecah teks menjadi token, menghapus kata umum, dan melakukan stemming atau lemmatisasi. Ketiga, ketika pengguna memasukkan kueri, sistem akan mencocokkannya dengan indeks dan memberi peringkat dokumen berdasarkan relevansi.
Namun, pendekatan klasik ini memiliki kelemahan besar ketika berhadapan dengan ambiguitas. Kata yang sama bisa memiliki banyak arti, frasa bisa ditafsirkan berbeda tergantung konteks, dan pengguna sering mengetik kueri yang pendek dan tidak jelas. Di sinilah disambiguation menjadi lapisan tambahan yang memberikan kecerdasan pada sistem IR.
Jenis Ambiguitas yang Dipecahkan dalam Information Retrieval Disambiguation Tutorial
Artikel dan panduan yang mengangkat information retrieval disambiguation tutorial umumnya memulai penjelasan dengan mengidentifikasi jenis ambiguitas yang muncul dalam bahasa alami. Ambiguitas ini bukan sekadar masalah linguistik, melainkan tantangan teknis yang harus dipecahkan agar hasil pencarian terasa “paham” kebutuhan pengguna.
Secara garis besar, ada beberapa tipe ambiguitas utama. Pertama, ambiguitas leksikal, ketika satu kata memiliki banyak arti. Kedua, ambiguitas semantik, ketika hubungan makna antar kata dalam kalimat bisa ditafsirkan lebih dari satu cara. Ketiga, ambiguitas referensial, ketika kata ganti atau nama merujuk ke banyak entitas yang mungkin berbeda.
Dalam sistem IR, ketiga jenis ambiguitas ini bisa menyebabkan hasil pencarian yang melenceng. Misalnya, pengguna yang mencari “python tutorial” kemungkinan besar menginginkan bahasa pemrograman, bukan reptil. Namun tanpa disambiguation, sistem mungkin tetap menampilkan konten yang tidak relevan.
“Ambiguitas adalah sifat alami bahasa manusia. Tantangan terbesar IR modern adalah menjembatani dunia yang ambigu ini dengan mesin yang menuntut kepastian.”
Teknik Disambiguation dalam Information Retrieval Modern
Setelah memahami jenis ambiguitas, tahapan berikut yang kerap disorot dalam information retrieval disambiguation tutorial adalah berbagai teknik untuk mengatasinya. Teknik ini berkembang seiring kemajuan pemrosesan bahasa alami dan pembelajaran mesin.
Salah satu teknik klasik adalah menggunakan kamus atau leksikon yang memuat daftar kemungkinan makna suatu kata. Sistem kemudian mencoba memilih makna yang paling cocok dengan konteks kalimat. Teknik ini sering dikombinasikan dengan aturan berbasis linguistik, misalnya pola tata bahasa tertentu yang mengisyaratkan makna tertentu.
Di era pembelajaran mesin, pendekatan statistik dan berbasis vektor semakin dominan. Model seperti word embeddings dan language model modern memetakan kata dan kalimat ke dalam ruang vektor sehingga kedekatan makna bisa dihitung secara numerik. Dengan demikian, sistem dapat menyimpulkan bahwa “python” yang sering muncul bersama “code”, “function”, dan “script” lebih mungkin merujuk pada bahasa pemrograman daripada hewan.
Di tingkat yang lebih tinggi, sistem juga memanfaatkan informasi perilaku pengguna. Riwayat pencarian, lokasi geografis, bahasa antarmuka, hingga perangkat yang digunakan dapat menjadi sinyal tambahan untuk membantu disambiguation. Misalnya, pengguna di Indonesia yang mengetik “Java” kemungkinan besar lebih sering diarahkan ke informasi tentang pulau Jawa dibanding bahasa pemrograman, kecuali ada konteks teknis yang kuat.
Menyusun Information Retrieval Disambiguation Tutorial yang Sistematis
Ketika sebuah panduan diberi judul information retrieval disambiguation tutorial, biasanya ada struktur pembelajaran bertahap yang memudahkan pembaca mengikuti alur. Struktur ini penting agar pembaca tidak tersesat di antara istilah teknis dan konsep abstrak.
Tahap awal biasanya dimulai dengan pengenalan IR dasar dan contoh ambiguitas nyata yang dihadapi pengguna sehari hari. Setelah itu, tutorial masuk ke konsep pemrosesan bahasa alami, seperti tokenisasi, pengenalan entitas bernama, dan analisis sintaksis. Tahap ini memberikan landasan agar pembaca paham bagaimana teks diurai oleh mesin.
Tahap berikut adalah pengenalan teknik disambiguation itu sendiri, baik yang berbasis aturan maupun berbasis pembelajaran mesin. Di sini, contoh konkret menjadi kunci. Misalnya, bagaimana sistem membedakan kata “bank” sebagai lembaga keuangan dan “bank” sebagai tepian sungai berdasarkan kata di sekitarnya. Tutorial yang baik biasanya menyediakan potongan kode, diagram alur, dan visualisasi hasil.
Terakhir, tutorial sering menampilkan studi kasus penerapan disambiguation dalam sistem IR nyata, seperti mesin pencari internal perusahaan, portal berita, atau aplikasi rekomendasi. Bagian ini menunjukkan bahwa konsep yang tampak teoretis tadi benar benar punya aplikasi langsung yang terasa dalam pengalaman pengguna.
Penerapan Information Retrieval Disambiguation di Mesin Pencari
Salah satu contoh paling mudah dipahami dalam information retrieval disambiguation tutorial adalah penerapan di mesin pencari web. Pengguna hanya melihat kotak pencarian sederhana, tetapi di balik itu ada rangkaian proses rumit yang berjalan dalam hitungan milidetik.
Ketika kueri dikirim, sistem pertama tama menganalisis teks kueri. Apakah mengandung entitas tertentu seperti nama orang, tempat, atau organisasi. Apakah ada kata yang lazim ambigu. Apakah pola kueri mirip dengan kueri populer lain yang pernah diproses. Dari sini, sistem mulai menyusun hipotesis makna.
Selanjutnya, sistem mengajukan beberapa interpretasi kueri ke indeks dokumen. Misalnya, untuk kata “apple”, sistem akan mempertimbangkan apakah pengguna mencari perusahaan teknologi, buah, atau sesuatu yang lain. Skor relevansi dihitung untuk tiap interpretasi berdasarkan sinyal semantik, perilaku pengguna sebelumnya, dan data agregat jutaan pengguna lain. Interpretasi dengan skor tertinggi akan mendominasi hasil yang tampil.
Jika sistem masih ragu, ia bisa menampilkan hasil campuran atau bahkan menambahkan saran kueri alternatif di bagian atas. Inilah bentuk kompromi ketika disambiguation belum sepenuhnya yakin, tetapi tetap harus memberikan jawaban cepat.
Information Retrieval Disambiguation Tutorial untuk Pencarian Internal Perusahaan
Selain mesin pencari publik, banyak information retrieval disambiguation tutorial yang menyorot kebutuhan di lingkungan perusahaan. Pencarian internal di organisasi besar seringkali lebih rumit karena istilah teknis, singkatan, dan jargon internal yang tidak ditemukan di kamus umum.
Dalam konteks ini, disambiguation harus memanfaatkan pengetahuan domain. Sistem perlu mengenali bahwa singkatan tertentu di satu perusahaan bisa berarti sesuatu yang sama sekali berbeda di perusahaan lain. Model bahasa umum saja tidak cukup, perlu adaptasi dan pelatihan ulang berdasarkan dokumen internal.
Tutorial yang membahas topik ini biasanya menjelaskan bagaimana membangun kamus istilah internal, melatih model pembelajaran mesin dengan data perusahaan, dan mengintegrasikan sinyal seperti struktur organisasi, departemen, serta proyek untuk membantu menafsirkan kueri. Misalnya, kata “portal” di sebuah perusahaan bisa merujuk ke nama produk tertentu, bukan sekadar istilah umum.
Information Retrieval Disambiguation Tutorial pada Bahasa Indonesia
Aspek lain yang menarik dalam information retrieval disambiguation tutorial adalah tantangan bahasa. Banyak contoh dan model awal dikembangkan untuk bahasa Inggris, padahal bahasa Indonesia memiliki karakteristik sendiri yang memengaruhi proses disambiguation.
Bahasa Indonesia kaya dengan kata serapan, singkatan, dan bentuk tidak baku yang sering dipakai di percakapan digital. Selain itu, imbuhan seperti me, di, ke, dan pe dapat mengubah bentuk dasar kata dengan cara yang tidak selalu mudah diurai oleh mesin. Ambiguitas juga muncul dari penggunaan kata yang sama untuk kelas kata berbeda, tergantung posisi dan konteksnya.
Untuk mengatasi ini, tutorial yang fokus pada bahasa Indonesia biasanya menekankan pentingnya korpus lokal, kamus istilah yang relevan dengan budaya dan kebiasaan bahasa Indonesia, serta penyesuaian model bahasa. Penggunaan data percakapan dari media sosial, forum lokal, dan portal berita berbahasa Indonesia dapat membantu sistem lebih akurat membedakan makna.
Mengintegrasikan Information Retrieval Disambiguation Tutorial dengan Pembelajaran Mesin Modern
Perkembangan model bahasa besar dan teknik pembelajaran mendalam membawa bab baru bagi information retrieval disambiguation tutorial. Kini, banyak panduan yang tidak lagi hanya menjelaskan algoritma klasik, tetapi juga bagaimana memanfaatkan model pralatih untuk disambiguation yang lebih canggih.
Model modern dapat memahami konteks yang sangat panjang, menangkap nuansa makna, dan melakukan penalaran sederhana atas teks. Dalam IR, ini berarti sistem bisa menafsirkan kueri yang lebih kompleks, seperti pertanyaan lengkap, bukan sekadar kata kunci. Disambiguation tidak lagi berdiri sebagai modul terpisah, melainkan terintegrasi dalam pemahaman bahasa yang lebih luas.
Namun, tutorial yang bertanggung jawab juga mengingatkan bahwa model besar bukan solusi ajaib. Mereka tetap membutuhkan data pelatihan yang baik, evaluasi ketat, dan pengawasan manusia, terutama ketika digunakan dalam domain sensitif seperti kesehatan, hukum, atau kebijakan publik. Integrasi yang tepat antara teknik klasik dan model modern sering menjadi kombinasi paling efektif.
Dengan memahami berbagai lapisan yang dibahas dalam information retrieval disambiguation tutorial, pembaca dapat melihat bahwa di balik satu kotak pencarian sederhana, ada dunia teknik yang kompleks, dinamis, dan terus berevolusi mengikuti cara manusia berbahasa dan mencari informasi.














Comment